总体而言,java线程池技术经历了两个阶段,第一阶段是我们需要自己通过自己写代码来实现线程池技术的,网上有不少现成的资料。总体来说,设计一个线程池包括以下几个类:
1)总体执行类
ThreadPool ,用来创建线程池,这个类还包括一些属性,如下:
a)任务列表
private static List<Task> taskQueue = Collections
.synchronizedList(new LinkedList<Task>());
b)线程池中的所有线程
public PoolWorker[] workers;
提供的方法中,包括构造函数,默认构造默认个数的worker并作为守护线程执行。
Execute方法,执行一个Task。
closePool方法,关闭pool
2)执行线程,即PoolWorker,每个PoolWorker都继承自Thread,即没新起一个worker就是一个新线程。Worker的run方法里面,主要工作就是从taskQueue中获取Task,并执行Task的run()方法。
3) 任务Task,一般都是一个实现Runnable接口的实现类。该类的run()方法就是具体要做的事情,你可以用来实现自己的业务逻辑。
以上的实现总体来说有一个缺陷,就是相对来说还是比较死的,线程数一般都是固定的,没有伸缩性。不能安装系统的吞吐量要求来增加或者减少线程。
因为线程池技术如此有用,而自身实现总有这样那样的功能缺陷,从5.0开始,jdk自身提供了线程池技术。比较完美的解决了以上问题,总体来说,主要包括以下几个类:
ExecutorService 线程池接口
ThreadPoolExecutor 线程池接口的默认实现类等,类图如下:
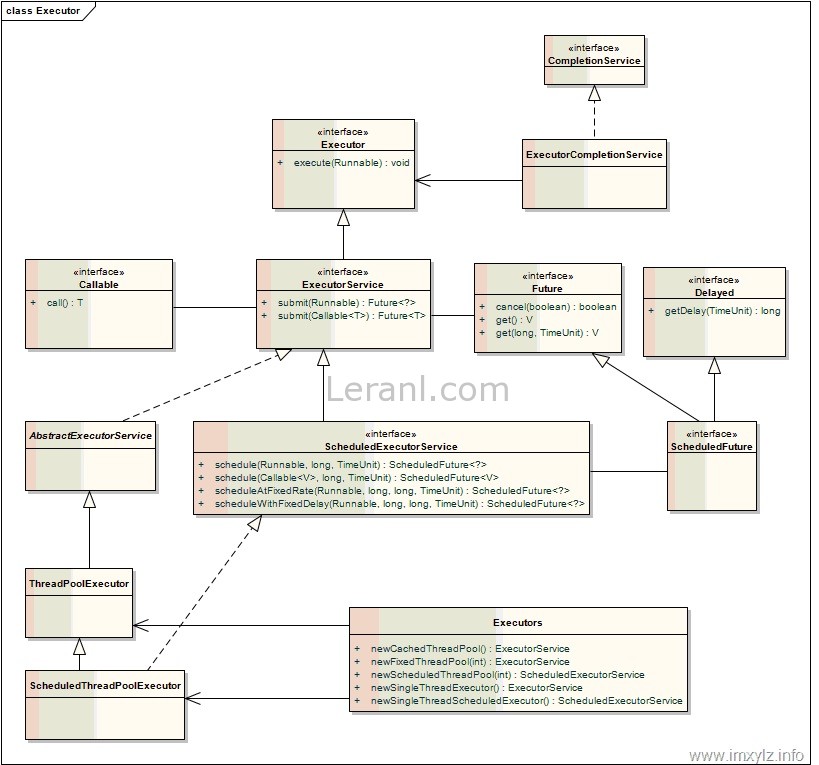
核心类ThreadPoolExecutor:常用构造方法为:
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,
long keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler)
corePoolSize: 线程池维护线程的最少数量
maximumPoolSize:线程池维护线程的最大数量
keepAliveTime: 线程池维护线程所允许的空闲时间
unit: 线程池维护线程所允许的空闲时间的单位
workQueue: 线程池所使用的缓冲队列
handler: 线程池对拒绝任务的处理策略
一个任务通过 execute(Runnable)方法被添加到线程池,任务就是一个 Runnable类型的对象,任务的执行方法就是 Runnable类型对象的run()方法。
当一个任务通过execute(Runnable)方法欲添加到线程池时:
如果此时线程池中的数量小于corePoolSize,即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务。
如果此时线程池中的数量等于 corePoolSize,但是缓冲队列 workQueue未满,那么任务被放入缓冲队列。
如果此时线程池中的数量大于corePoolSize,缓冲队列workQueue满,并且线程池中的数量小于maximumPoolSize,建新的线程来处理被添加的任务。
如果此时线程池中的数量大于corePoolSize,缓冲队列workQueue满,并且线程池中的数量等于maximumPoolSize,那么通过 handler所指定的策略来处理此任务。
也就是:处理任务的优先级为:
核心线程corePoolSize、任务队列workQueue、最大线程maximumPoolSize,如果三者都满了,使用handler处理被拒绝的任务。
当线程池中的线程数量大于 corePoolSize时,如果某线程空闲时间超过keepAliveTime,线程将被终止。这样,线程池可以动态的调整池中的线程数。
unit可选的参数为java.util.concurrent.TimeUnit中的几个静态属性:
NANOSECONDS、MICROSECONDS、MILLISECONDS、SECONDS。
workQueue我常用的是:java.util.concurrent.ArrayBlockingQueue
handler有四个选择:
ThreadPoolExecutor.AbortPolicy()
抛出java.util.concurrent.RejectedExecutionException异常
ThreadPoolExecutor.CallerRunsPolicy()
重试添加当前的任务,他会自动重复调用execute()方法
ThreadPoolExecutor.DiscardOldestPolicy()
抛弃旧的任务
ThreadPoolExecutor.DiscardPolicy()
抛弃当前的任务
类Executors提供了一系列的工厂方法创建一些常用的线程池,
newSingleThreadExecutor:创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
newFixedThreadPool:创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
newCachedThreadPool:创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
newScheduledThreadPool:创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
newSingleThreadExecutor:创建一个单线程的线程池。此线程池支持定时以及周期性执行任务的需求。